Kenneth Blomqvist
I'm an entrepreneur and robotics engineer. Currently, I'm building Witty Machines.
Previously, I was an early software engineer at Wolt and Webflow. I used to write software at Flowdock. I founded the Junction hackathon at the Aalto Entrepreneurship Society. I completed my Phd at ETH Zürich at the Autonomous Systems Lab. My research was on teaching robots perception skills quickly from few examples.
Writing
What Switzerland Gets Wrong
09 Mar 2025Neural Stereo Depth Matching Onboard the Luxonis OAK-D
14 Nov 2022Collecting RGB-D Datasets on LiDAR Enabled iOS devices
10 Mar 2021We Need Organic Software
29 Nov 2020Projects
Panoptic Vision-Language Feature Fields
January 2024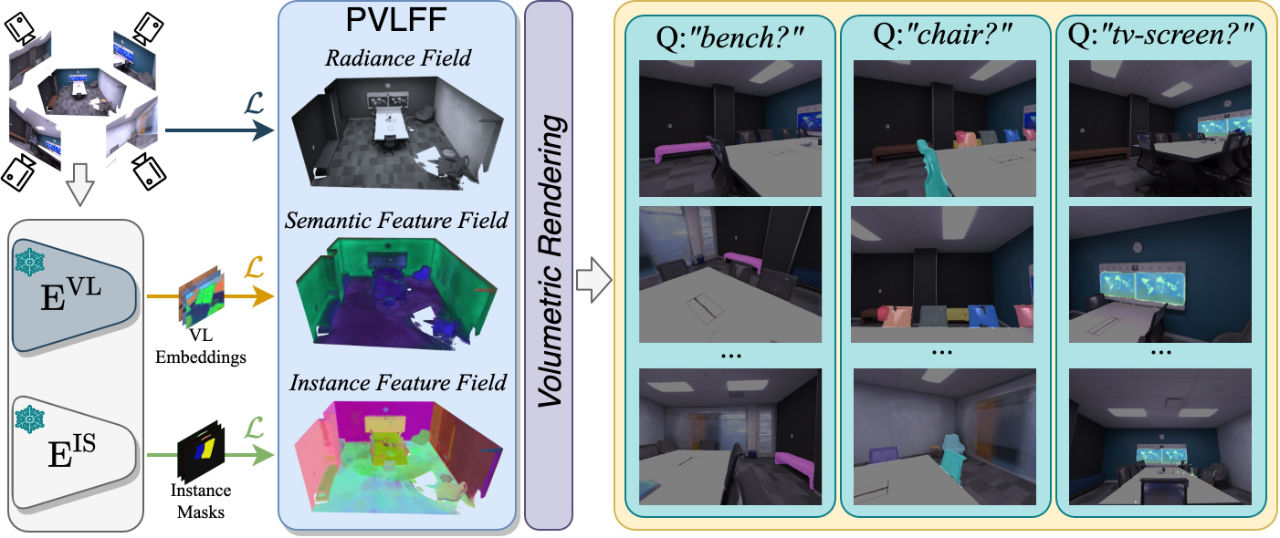
Haoran Chen extended vision-language feature fields to also segment instances of objects, creating an open-vocabulary panoptic segmentation system. This means we can not only figure out which parts of the scene are relevant for a query, but also tell how many of those relevant objects there are. The work was published in IEEE Robotics and Automation Letters.
See the project website for the paper, video and more details.
ISAR: A Benchmark for Single- and Few-Shot Object Instance Segmentation and Re-Identification
January 2024
Nicolas Gorlo presented his work on few-shot instance segmentation and re-identification at WACV 2024. I had the great pleasure of advising Nicolas on this project.
To build robots that can be quickly be taught about new objects and concepts, we first need to solve the problem of segmenting and re-identifying objects in images from few examples. Here, we present a benchmark and baseline algorithm for segmenting and re-identifying objects from sparse examples in the form of a few clicks from a user. The algorithm then has to segment the objects in future frames and re-identify the same object in different contexts.
See the project website for all the details.
Neural Implicit Vision-Language Feature Fields
March 2023
Neural Implicit Vision-Language Feature Fields are an approach to dense scene understanding. It is a neural implicit scene representation with additional vision-language feature outputs, which can be correlated with text prompts, enabling zero-shot open-vocabulary scene segmentation. You can basically type in the thing you are looking for, and it will highlight the relevant parts of the scene.
The scene representation can be built up incrementally, it runs in real-time on real hardware, it can handle millions of semantic point queries per second and works for any text queries. See here for the research paper.
Autolabel
September 2022
Autolabel is a tool to produce dense segmentation maps for RGB-D video through volumetric segmentation. Behind the scenes, it uses a semantic NeRF model to infer a 3D segmentation of the scene from very sparse user labels. The learned representation is then used to render dense segmentation maps for given viewpoints.
To improve segmentation performance, we explored using pre-learned feature maps as an additional supervision signal. We wrote about the work in our research paper.
Stray Studio and Command Line Toolkit
August 2021
The Stray CLI and Studio is a software toolkit for solving computer vision problems. It allows you to reconstruct 3D scenes from RGB-D video, annotate the scenes with high-level semantic information and fit computer vision algorithms to the annotated scenes.
Object Keypoints
June 2021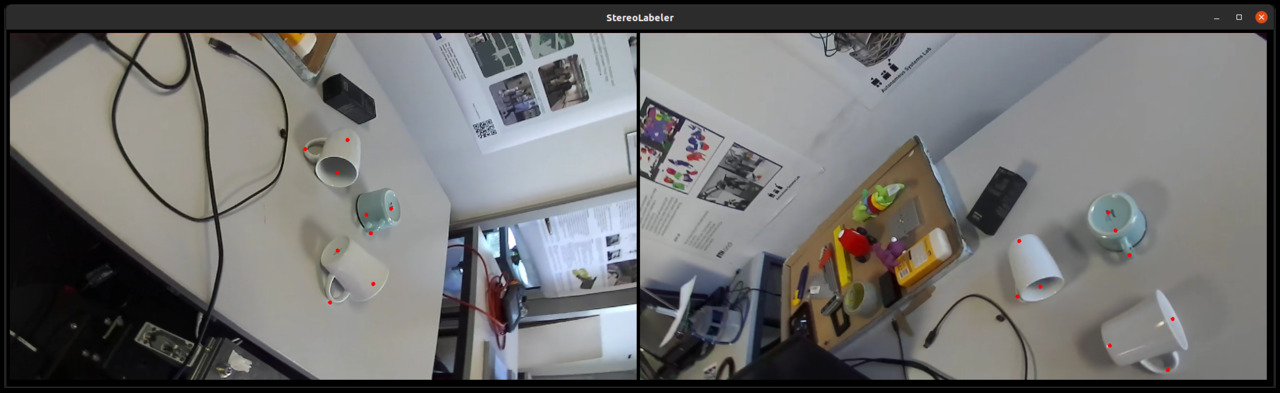
Object Keypoints is a simple method to build a model that can track pre-defined points on objects in 3D. It includes a way to scan the objects using a robot arm, a tool to annotate the points, a script to fit the model and a pipeline to detect the 3D points at runtime using the trained model. It can handle multiple objects in a frame simultanously and does not require object instance segmentation.
Stray Scanner App
March 2021
Stray Scanner is an app for collecting RGB-D datasets with an iPhone or iPad with a LiDAR sensor.
Mobile Manipulation Demo
June 2020
We created a simple demo to investigate the limitations of state-of-the-art methods in mobile manipulation. The robot is tasked to go through an office to find an object, pick it up and return with the object. It uses SLAM, motion planning, grasp planning and some perception algorithms to get the job done.
We wrote about the work here. A video of the demo can be found here.
Particle Simulation
May 2020
Autonomous Race Car
February 2019
We built an autonomous race car using an old 1/10th scale radio-controlled touring car. It uses an Nvidia Jetson TX 1 which communicates with some rc electronics through an Arduino board. It has an RGB camera at the front and an IMU sensor. Velocity is measured through a sensor inside the brushless motor.
The car be both be driven using the regular RC remote or autonomously reading commands from the Jetson. The commands from the remote can be recorded and used for learning. The picture is from an early version which used a Raspberry Pi instead of the Jetson.
We used the platform to do some research into driving the car using reinforcement learning. Most of the code is available here.
Deep Convolutional Gaussian Processes
October 2018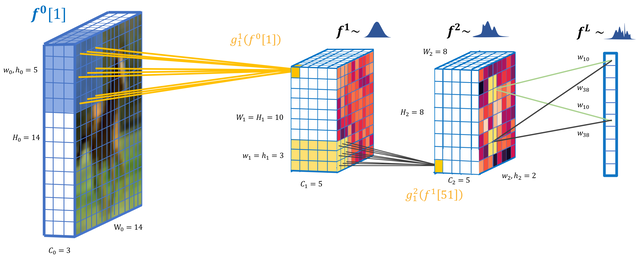
In this project, we basically tried to build a modern convolutional neural network using Gaussian processes. We ran the model on some image classification benchmarks. At the time, we were able to get better results than any other GP based method, but results are still behind the advanced neural network based techniques. Scaling these large GP models still remains a challenge.
The results can be found in our paper and code is available here.
Get in touch
You can find me on GitHub, Twitter, LinkedIn and Goodreads. Feel free to get in touch via email.